javax.persistence.Query query = manager.createQuery(...);
query.setHint("org.hibernate.cacheable", true);
RHQ 4.7
Caching
This document wants to give some ideas on how to use cacheing techniques to improve the scaling and responsiveness of RHQ. The current approach is very database centric and very much relies on a fast database.
Triggered by discussions about Hadoop on the forum,
our very own Infinispan and an episode of SE-Radio about memory grids I got the idea of revisiting some of our db-bound architecture and to think about caching stuff in memory.
First we will start off with some numbers to give an idea about data volumes.
The next section will then talk about different kinds of caches. Then we'll talk about candidates for caching.
RAM is cheap those days. 8GB DDR3 notebook memory costs around $150.
A Dell Poweredge T710 with 2 Xeons and 64GB of RAM costs around $6-7k; another 64GB are $1600 on top.
Kinds of caches
This section describes various possible kinds of caches; some are more applicable to certain kinds of objects than others.
Hibernate 2nd level cache (clustered in HA)
Hibernate allows to cache objects in 2nd level cache and also have this as distributed version so that in a HA scenario changes can be published to other nodes, so that a) transactional integrity is maintained and b) the other node(s) will not hit the DB for the data, but can also get it from the cache.
The cache is (mostly) transparent for the application and can not directly be from Java code (like access in a map), but only indirectly via SQL statements. Like with the 1st level cache, cache regions need to be flushed if direct sql access has modified the data in the database.
Hibernate query cache
This cache allows to cache the IDs of query results. So if you run a query 5 times in a row, and you do not change the database content in between, only the first query will hit the DB and for the subsequent ones, the cache will know that the db content has not changed and thus return the same list of entity IDs.
To use this cache, a Hibernate cache provider needs to be enabled and the query cache as well. Queries that should be cacheable, also need to indicated this to Hibernate.
Special object caches
This kind of cache just keeps objects that are read-mostly in memory; access to the cache will need changes in the application logic and is not transparent. Unlike the Hibernate second level cache this cache would be accessed like e.g. a Map or Set and not via SQL.
It would allow to keep central objects / data structures in memory and bypass the expensive database queries.
Using a distributed cache (with M/R)
This scenario goes into the direction of using a memory grid / distributed cache / backend store like Infinispan 5 or Apache Hadoop. Common to both is the possibility to apply map/reduce functionality to obtain data from them. Which would have the advantage to "outsource" computation of derived values to the respective backends, which can either compute the data on demand (e.g. give me the average foobar of this group) or on ongoing / periodical fashion, where the results would be obtained from a different storage area.
As a lot of our data is very independent of each other, it is relatively easy to find rules for partitioning (e.g. the schedule for metrics).
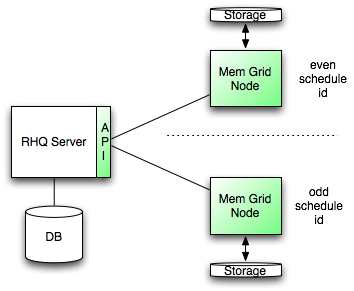
In above example, the data for the two memory grid notes are partitioned by even/odd schedule_id. This way, the api knows which node to query for data.
Candidates for caching
Usually read-mostly data is perfect for caching. ResourceTypes for example do not change (much) after they have been loaded in server startup. There is no point in repeatedly doing expensive queries on the database for those objects.
Availability
Availability data is run-length encoded meaning, that we do not store for each availability report that is coming in a new entry in the database, but only if the reported availability has changed from the previous one. In order to achieve this, we need to look up the last availability in the database and compare it with the new record. If the state does not match, we
update the old record to get an end time and append the new record in the database
Caching would transparently after server start record the reported availability and from there on serve to do the comparison. Only when the values differ, the database would be hit to update the old record and append the new one; the latter would then end up in the cache.
Such caching should help a lot with full availability records coming in for (agents with) a large number of resources, as normally resources are supposed to be up for a very long time.
Caching can be local per server, as the cache region is bound to an agent. When an agent disconnects, its cache region could be fully purged (in a HA scenario).
Metrics
50k metrics per minute are 3000k per hour.
One MeasurementDataNumeric object is 72 Bytes in size (add some more for storing in a list or map)
so 3 M metrics * 72 bytes = 210 MBytes for one hour of metrics data.
So a commodity hardware could easily store 12h of numeric data, which would
allow to do
-
1h compression and 6h compression in memory
-
satisfy most metric graphs requests (remember 8h default) from memory
With such a big setup usually more than one server is available and the amount of memory
would be larger. This could even allow to do keep the 6h data and compute the 1d average
from it as well.
Resources and ResourceTypes
Another interesting area for caching would be Resources and ResourceTypes, as we have
quite a lot of queries that operate on the relatively static Resources and ResourceTypes.
7222 resources take 2.2MB so 140k resources would take around 40-50MB of (cache) memory.
Queries like
SELECT rr FROM Resource rr WHERE rr.id = :resourceId AND rr.parentResource.parentResource.parentResource.parentResource.parentResource.parentResource = r)
are very expensive on the database. While in memory this is just following some pointers.
Subject / Role / Resource-Group-Mappings
Permissions also change rarely (mostly when users are added or removed and resources/groups are added or removed). So those are perfect candidates for pre-calculation and cacheing.